First published under https://www.search-one.de/chatgpt-fehler/ by Kai Spriesterbach
The hype around ChatGPT is the biggest hype I have witnessed in the 40 years I have been on this earth. This chatbot allowed anyone to easily talk to an artificial intelligence for the first time. It caused a real AI explosion. Never before in human history has a product gained so many users so quickly. In the first two months, OpenAI’s chatbot already had 100 million registered users. But I have also never read so much nonsensical statements about a product as I have about ChatGPT!
If you look around on blogs, Twitter, LinkedIn or one of the many prompt communities where users share the supposedly best tips and tricks around the use of ChatGPT, you notice how seductive such hype can be on us humans. Everyone wants to be the first to share a new tip on ChatGPT that no one has ever heard before.
While researching for my current non-fiction book Richtig texten mit KI – ChatGPT, GPT-4, GPT-3 & Co., I came across a whole series of popular misconceptions and misunderstandings that I would like to clear up in this article.
So that you don’t fall for this bullshit, let me clear up the biggest misconceptions surrounding ChatGPT. Some of them are just minor inaccuracies, but others are such fundamentally wrong assumptions that they can actually make working with artificial intelligence dangerous!
1st mistake: Incorrect use of terms and concepts
One of the most common mistakes I have encountered in recent months is to confuse ChatGPT with the major language models behind it. Sometimes people talk about ChatGPT-4, like in this example, which does not exist:

Fact: ChatGPT is OpenAI’s chatbot, which can be accessed via the website https://chat.openai.com/. GPT-3, GPT-3.5 and GPT-4, on the other hand, are the large language models of OpenAI that can be used via programming interfaces, the so-called APIs, and are also behind ChatGPT. But most other commercial AI text tools like Jasper, Frase, Neuroflash and co. also use these interfaces to give their products the capabilities of artificial intelligence. As a paying user of ChatGPT PLUS, ChatGPT lets you choose between GPT-3.5 and the newer GPT-4, which has probably led to misnomers like ChatGPT-4.
At first glance, this may only be an inaccuracy, but it shows me that the author has not studied the technology behind it in depth. So if you read something like this somewhere, you should be careful with the information and tips from this person.
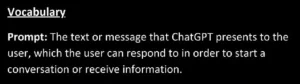
And lo and behold, the same author confuses the term “prompt”, which stands for the instruction to an AI, with the response, i.e. the output of the AI, only one page further on:
But that’s not all. Instead of talking about tokens in the length limit, the author claims that GPT-4 would be able to handle up to 25,000 words, as opposed to the alleged 8,000 of GPT-3.5:

I understand the desire to specify the limit in words, although OpenAI can only specify them in the form of tokens. However, it is not so easy to say how many words make up the limit specified in tokens. This is because the term “token” refers to a unit of text that is processed by the AI as a separate unit. A token can be a word, a number, a punctuation mark, a symbol or even just part of a word. A rule of thumb is that a token is on average about ¾ of a word in the English language. In an English text, 100 tokens would therefore be about 75 words. German words, however, contain more tokens on average, so that a German text of 100 tokens can sometimes contain only 50 words. So a statement about the limit of ChatGPT is only really meaningful in tokens.
The best thing, however, is that neither 8,000 words nor 8,000 tokens is the limit of GPT-3.5.
Here, too, the author has done his research too sloppily, because GPT-3.5 actually has a token limit of 4,097. GPT-4 actually has 8,192 and only in a special variant, namely the largest and also most expensive GPT-4-32K model, a proud 32,768 tokens.
Another fine example of bullshit can be found in the same “ChatGPT Guide” right in the next paragraph. In it, the author claims that GPT-4 has been trained using gigantic amounts of text and mentions “100 trillion parameters” as a possible order of magnitude for the amount of text:

However, this conflates two different things that actually have nothing to do with each other. Namely, the amount of training data with which the language model was trained and the number of parameters within the model that ensure that it can develop its complexity and “intelligence”. Consequently, such a statement makes no sense at all!
But hidden in the sentence is another error, which is the most popular misinformation surrounding the new GPT-4 language model: In many places, the number of parameters of GPT-4 is given as “100 trillion”.
You may have seen this graphic before, which is meant to illustrate the number of parameters of GPT-4 compared to its predecessor GPT-3. For a few days, this was probably the most shared graphic on LinkedIn:

Unfortunately, this is complete bullshit, because the increasing commercialisation of language models and the increasing competition from Google, Meta, Aleph Alpha and co. ensures that people at OpenAI no longer talk in such detail about the latest advances. No, GPT-4 has neither 100 trillion parameters nor 1 trillion parameters.
The truth is that OpenAI has not published any more detailed information on GPT-4’s structure to date. It is neither known to what extent the architect has changed in comparison to its predecessor GPT-3, nor exactly how many parameters the model has or on the basis of which training data it was trained.
2nd mistake: confusing the language model with a knowledge model
No question: It is extremely entertaining and tempting to ask ChatGPT about things you don’t know yourself or to have it write texts containing statements that require very broad general knowledge or even special expert knowledge. To some extent this even works, but it is not easy to tell when ChatGPT has “made something up” and when a statement has been included in the training data frequently enough that it is actually true and not just coincidental. Especially if you are not well versed in the subject yourself, it is almost impossible to detect confident false claims made by the AI.
The language models behind ChatGPT, for example GPT-3.5 and GPT-4, are designed to produce human-like texts. They do this by analysing the structure and context of speech. However, these models do not understand the actual content of the texts and are therefore not knowledge models.
These models cannot recognise, store or retrieve facts and information. There is no database or structured storage of information from the training data in them. They do not store texts in their original form, but only calculate the probability of individual words or word components based on the preceding words in the training data. Despite these limitations, language models can indeed produce amazing results, but one should first look critically at each generated statement.
This only really becomes clear when you take a look at the probabilities of the individual words or tokens:
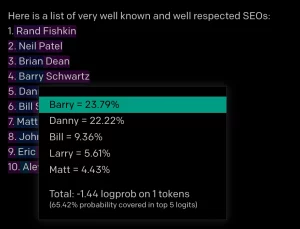
In this example, I had GPT-3 generate a list of the best-known and most respected SEOs. As a click on “Barry” reveals, the probability of a certain “Danny” being in 4th place instead of Barry Schwarz was extremely close, followed by “Bill”, “Larry” and “Matt”. In the context of SEO, Barry is then followed by “Schwartz” and Danny is then followed by “Sullivan”, resulting in (in this case) a list of actually existing persons.
As you have hopefully noticed while reading this article, ChatGPT is far from perfect. Because of its simple operating principle, ChatGPT can misrepresent information even in summaries of existing texts. In addition, ChatGPT is not up to date with the latest knowledge: Since ChatGPT was trained on texts that were available at a certain point in time, it is not always up to date with the latest knowledge. It is important to check the content generated for currency and accuracy.
For example, if you instruct ChatGPT to act as an academic and research a topic of your choice and present the results in the form of an essay or article, you can instruct the AI to find reliable sources, structure the material well and support it with citations, but this does not mean that it will only output correct information.
I personally advise against such a process in general, because to recognise what is correct and what is incorrect from it is a real syssyphus task. Unless you are an expert in the subject, you have to check every single statement, which in the end is even more time-consuming than first doing a research of facts and sources and then using ChatGPT only to summarise them.
You can have the AI write a paper with hypotheses first and then try to find evidence and sources for its claims, but that is not how science works. Real science first looks at all the sources and facts and then draws its conclusions from them. Not the other way round. So please be extremely careful when you publish statements, data and information from the AI, or even adopt them as your own. Always do a fact check!
Error 3: ChatGPT cannot access the internet
No matter if ChatGPT is supposed to write a summary or if you let it write an article that is supposed to be better than an existing text from the internet. It’s complete nonsense to use a URL in a prompt, because ChatGPT (currently at least) is neither able to retrieve the content on that page live, nor to dig up the exact text from the training data based on a URL.
ChatGPT will use the words in the URL, just like any other word in the statement, to generate the most likely response that looks like it actually retrieved the web page!
It is even more foolish to think you can get ChatGPT to simply write a better article than your competitor’s with an “outrank article prompt”. But this is not only found in numerous ChatGPT guides and prompt communities, but is also blithely shared by one or the other SEO out there without having a clue what is really happening.
By the way, OpenAI is currently working on plug-ins that solve exactly this and is even testing a new model that can access the internet. But the so-called “browsing” model is currently still in the alpha phase and is only available to a very few, selected test users.
One example of what browsing can do for ChatGPT users is the ability to find and access current information. For example, ChatGPT can access the latest information about the current Oscars while at the same time using its poetry writing skills. This shows how browsing can enhance ChatGPT’s user experience. The plugin allows language models in ChatGPT to read information from the internet, expanding the amount of content they can meaningfully talk or write about.
Error 4: Overestimating ChatGPT’s self-disclosure capabilities
Because ChatGPT’s “knowledge” is derived solely from statistical analysis of large amounts of text, it is very poor at answering specific questions about details about itself. For example, ChatGPT cannot know what percentage of the training data was in a particular language, or which websites or authors were included in the training data and how often.
ChatGPT does get some basic information about its own characteristics from the developers via the so-called system prompts, for example that it is called “ChatGPT”, is a chatbot and should answer as neutrally and factually as possible, but for other questions about specific details, the language model behind ChatGPT simply rhymes something together based on the word probabilities.
For example, in the following example, ChatGPT claims to have been trained solely on English texts, only to admit in the same chat that it is possible that German-language texts could also be included in the training data (screenshot in german):

(Chat GPT claims that all training data is in english just to add in the 3rd answer that maybe some german training date would be used also)
Do not use ChatGPT to learn about ChatGPT. The information that would be necessary to answer these questions could not yet be contained in the training data in September 2021!
Error 5: Mixing up texts or topics that are too long
If you look around a bit on YouTube on the topic of ChatGPT, you will quickly stumble across videos in which someone claims to have earned an absurd amount of money by having ChatGPT write a book and then selling it on Amazon via the Kindle Direct Publishing programme. Anyone who has spent a little more time with ChatGPT knows that these can only be bait-and-switch offers and promises of salvation from some rip-off entrepreneurs, because ChatGPT is not technically capable of writing an entire book.
But many alleged ChatGPT experts also claim that it is possible to have a complete book written with just one click.
By limiting the maximum output of the language model, both the length of the instruction to ChatGPT and the maximum length of the AI’s response are limited. Depending on the model used, ChatGPT can currently output a maximum of 1,700 words at a time.
Funnily enough, one hardly finds any critical comments on prompt sites like AIPRM about such bullshit prompts. Apparently no one looks at the beginning of the generated book any more than that:
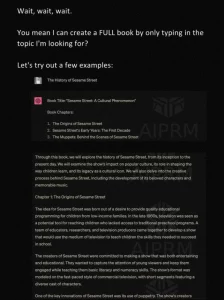
Of course, one can now get the AI to continue the output over and over again and then copy the generated parts into a document. However, in this case the story will neither have a red thread nor be consistent in itself.
Due to the limited input, ChatGPT cannot even see the beginning of the book, for example, even though it wrote it itself! So it happens quickly that roles change their names, the plot jumps absurdly back and forth, actions are repeated or the whole thing looks like a random stringing together of chapters from random foreign books.
It is a real art to make the overall context of the story clear to the AI again with every query and to tell it exactly where it is in the story, so that the individual chapters are told in detail and excitingly, but at the same time the view of the big picture is not lost.
Just as with its output, ChatGPT is also limited in its input. In the case of an overlong text that the AI is supposed to paraphrase, summarise or translate, one does receive an error message in ChatGPT, but self-proclaimed “prompt engineers” have long since come up with the idea of dividing a longer text into several pieces and gradually giving them to the AI to “eat”. After the piece-by-piece input, these would-be gurus then instruct ChatGPT to process the entire text.
However, this inevitably leads to the AI making something up, because this alleged “trick” cannot be used to undermine the limitation of the input and output of the language model!
The only way to process longer texts in ChatGPT is to copy the text piece by piece into the chat window, repeating each time the instruction what to do with it. The overall result, however, must then be put together from the partial results. Unfortunately, it is not possible to analyse the entire content at once, for example “to find the core message”.
ChatGPT therefore takes into account approximately the last 1,500 to 1,700 words in a chat. By the way, it doesn’t matter whether this is an instruction from you or an output from the chatbot. Only in this way is it possible to ask questions, have things rephrased or continue tasks. But this also means that ChatGPT “sees” the answer to each question and, depending on the length, also previous questions and answers when you ask a new task.
For example, if you first discuss ethics with the AI and then suddenly want to know what colour apples are, the answer will probably be much more philosophical than if you ask ChatGPT about the colour of apples in a new chat sale.
Ideally, you should start a new chat in ChatGPT for every new task, and certainly for every new topic. This will ensure that previous information and instructions do not get in the way of solving the new task.
6. believe ChatGPT understands everything and can do everything
For everyone who thinks the topic of AI is just a storm in a teacup and will pass just as quickly as the Crypto-Scam or the Metaverse bullshit, you can find someone who already believes everything about the current AI.
For example, on prompt-sharing sites you can find sometimes absurd instructions to the AI that give it tasks that it simply cannot solve at all. But instead of saying that it is not up to the task at all, ChatGPT, similar to asking it to summarise a web page based on a URL, will make up something based on the known information, which then looks in part as if it has actually performed the desired task.
For example, a popular prompt at datafit, the so-called “Human-like Rewriter – V1.6” uses, among other things, the instruction “Enabled Plagiarism: Disabled Anti-Plagiarism: Enabled Uniqueness: 100%”, although ChatGPT is neither able to understand whether a generated text might be plagiarised, nor to prevent this by means of a simple instruction.
Neither is ChatGPT able to understand what the instruction “Please format the generated blog article in a professional format and not an AI format.” means, whereas the instruction “Utilize uncommon terminology to enhance the originality of the piece” can actually understand and implement the language model.
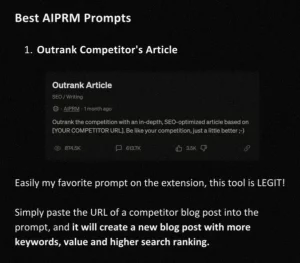
I’ve actually seen prompts like “Outrank the competition with an in-depth, SEO-optimised article based on [URL]. Be like your competition, just a little better ;-)” which were celebrated as if they were the holy grail of SEO intelligence.
It is equally nonsensical to ask ChatGPT for specific information, such as a list of search terms including search volume and SEO competition density, or a list of the largest cities in a country with the number of inhabitants. Here ChatGPT will generate the most likely answer, but it may not be correct!
ChatGPT has just been trained to generate texts that we humans like. Therefore, users of such prompts often do not even notice that their statement or at least parts of it basically do not make sense. Please do not use prompts unthinkingly. There are countless stupid prompts in prompt engineering communities, browser plugins or collections of the supposedly best prompts out there.
However, for such tasks in the future, the new “code interpreter” model could be used, which is currently still in alpha phase and only available to a very small number of users in ChatGPT. This allows ChatGPT to work in a protected environment with a Python interpreter. During a chat conversation, the session remains active and different code calls can even build on each other. It is also possible to upload files and download results.
The generated and executed Python code is also displayed in the process, so it can be adapted and re-executed elsewhere or in ChatGPT at any time. However, the aim is not to turn ChatGPT into a development environment, but to generate and use short code snippets to solve concrete tasks that the language model alone cannot perform (for example, arithmetic operations or the generation of plots, diagrams or images).
The special feature is that the experimental model should independently recognise when it needs Python code to complete a task, then write it itself and execute it directly!
This enables, for example, the analysis and visualisation of data up to 100 MB, such as tables with financial data. Especially for people without Data Science and Python knowledge, this opens up new possibilities.
Summary and conclusion
Having looked at the biggest mistakes in using ChatGPT in this article, using this fascinating AI technology for your writing should now become easier and more effective. But the journey into the world of generative AI has only just begun – there is so much more to discover and learn.
ChatGPT is only a tool, and thus only as effective as the person using it. You could even say that the AI is only as smart as the person using it, at most. Creating effective ChatGPT prompts requires careful thought and attention to detail. It’s easy to make mistakes that can massively affect the effectiveness of your prompts and the overall quality of the results.
In general, it is important to give ChatGPT enough information to understand the context and purpose of the conversation. Make sure your prompts are short and precise, and avoid unnecessary details or instructions. While open-ended questions can be useful for getting more detailed answers, overly vague or open-ended prompts can be confusing and difficult for the ChatGPT to understand. Make sure you give enough context and clues to guide the conversation in a meaningful way.
So that this doesn’t happen: Get my book
Get the in-depth non-fiction book on writing with AI now, which will help you understand how AI works, even covering the latest language model in ChatGPT namely GPT-4. When ChatGPT was introduced, I had already been working for more than a year with AI text tools based on GPT-3, the predecessor of the great language model GPT-3.5 behind ChatGPT. In the meantime, its successor GPT-4 has been published and I have packed my knowledge and experiences into my book “Richtig Texten mit KI: ChatGPT, GPT-4, GPT-3 & Co.”, which will be published by mvg Verlag on 23 May.
PIC: Midjourney