
First published by Astrid Kramer under https://www.df.eu/blog/indexierung-steuern/
A lot helps a lot – what was still true in the early days of SEO and resulted in creative excesses such as keyword stuffing, five H1s on a page or link spam has not worked for a long time. Google is getting better and more demanding every day and does not like to be bombarded with content or signals that are of inferior quality. Instead, Google continues to pursue its very own goal: to provide users with the one, best result for their search query.
As Google’s former press officer Stefan Keuchel said to me back in 2010: “The fact that we return 100,000 results for a search is not a good sign for us. It’s a sign that we’re still not managing to deliver that one, right result that that particular user wants to get in that exact second in their search history.” Yes, that sounds a bit scary. But clearly points the way to where the journey should have been going for a very long time. And ideally, this journey should not be hindered by web publishers who throw more and more content and URLs at Google, of which only a fraction may have any relevance at all.
As Bastian Grimm aptly put it during his keynote at SEOkomm 2022 in Salzburg: “Crawling costs money. It is no coincidence that Google & Co. provide tools ranging from ping to XML sitemap to assist the search giants in capturing the correct content. After all, search engines are also interested in conserving their own resources and simply saving money.”
So what is a good SEO to do? Besides the usual homework such as identifying and serving search intent, building a technically clean page, organically generating backlinks and triggering verticals, one job is usually still far too low on the to-do list: cleaning up. One goal in SEO should be to ensure that only the URLs and content that should really end up there end up in the index. Some tools and tricks, which are presented in the following, can help.
The XML Sitemap: direct communication with Google
The XML sitemap is a wonderful tool for communicating directly with Google about what content should end up in the index. In addition, you get concrete feedback on which content might be in trouble.
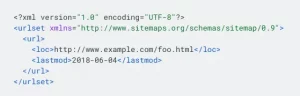 Example of an XML sitemap. Source: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap
Example of an XML sitemap. Source: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap
To make the most of these feedback opportunities, it helps to create granular XML sitemaps and store them accordingly in the Search Console. One way to do this, for example, is to divide XML sitemaps according to template, i.e. an XML sitemap for product pages, one for category pages and one for guidebook articles. Above all these sub-sitemaps is the index sitemap, which is a list of all existing sitemaps. With a granular approach, you can see at a glance whether Google is having problems indexing the product landing pages, for example, or whether many of the category pages are being ignored.
But even a quick and dirty XML sitemap that is generated automatically (there are many free tools for this on the web or corresponding plugins for the CMS, for example https://www.xml-sitemaps.com/ or the Yoast SEO plugin for WordPress) helps immensely with SEO. Of course, especially with the XML sitemap, you have to make sure that you do not present any URLs to Google and other search engines that are not index-relevant. In other words: URLs with 301 or 404 status codes or thin content (we will come back to this later) should not even be listed in the XML sitemap. Instead, index-relevant images and videos should be listed accordingly in order to push their indexation. Separate XML sitemap formats are also available for both media, which enable the transmission of detailed information on the respective media.
Of course, the same applies here: less is more. For example, it does not help to store a <priority>1.0</priority> for every URL entry in the XML sitemap. <priority>1.0 means that the corresponding URL has a priority of 1, i.e. the highest possible priority, and should therefore be given priority.
As we have often seen elsewhere (webmasters still try to get Google to look at their page every day with a meta tag revisit-after – no, it doesn’t work like that), Google does not allow itself to be dictated how it should treat and prioritise URLs. That is precisely what the in-house algorithm is there for. In the case of the XML sitemap, John Mueller has explicitly said that a specification like <priority> is ignored by Google. It is therefore better to make the XML sitemap as slim and performant as possible. A file size of 50 MB or 50,000 URLs is the end of the line anyway and another XML sitemap must be created.
Please do not confuse: the robots.txt
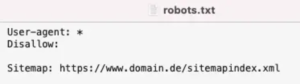
The robots.txt is often used for indexing but is unfortunately completely unsuitable. The robots.txt contains instructions for various crawlers on which pages should be included in the crawl. The file stored in the root of the domain can, for example, block entire directories for a bot so that it does not even call up this directory for crawling.
 Example of a robots.txt
Example of a robots.txt
However, this does not mean that pages that are excluded from crawling automatically do not end up in the index. Often the opposite even happens, which can then lead to errors in the indexation control. An example: if I permanently forward page A to page B via a 301 redirect, but prohibit the crawling of page A via robots.txt, it can happen that the bot does not recognise the redirect of the page because the HTTP header of the file in question is not read. The URL ends up in the index despite active redirection. This is a very unattractive result. The same applies to “noindex” instructions in the HTML source code, which we will discuss in more detail in the next section. This instruction is also not even seen by the bot if it is not allowed to crawl the page. In short: explicit bot instructions unfortunately have no effect if I specify via robots.txt that the bot is not allowed to crawl the page at all.
Please, noindex me!
Independently of external files such as XML sitemap and robots.txt, I can of course also say directly as an HTML document that I do not want to be indexed. The HTML statement <meta name=”robots” content=”noindex”> in the header of an HTML file clearly communicates that this page is not intended for indexing by a search engine. This so-called robots meta tag defaults to “index”, so it is not mandatory that this information be stored. Additional specifications such as “follow”, for example, instruct bots to follow the links on a page and pass on link juice. In this case, the combination of “noindex,follow” is interesting, as this robots meta tag excludes a page from indexing, but at the same time tells the bot that the links on the page should still be followed.
Files that do not have a writable HTML header, such as PDF or image files, can use the HTTP header X-Robots tag in this case. In this HTTP header instruction, all instructions can be stored that can also occur in the previously described robots meta tag.
Ping me on, just when you go-go
Not only the XML sitemap can be used to inform search engines about content to be indexed. A very old and still usable instrument for indexation control is the ping. In Search Console, for example, I can submit individual URLs for re-examination. As usual, Google does not support spamming here. So it is of no use at all to ping a new URL every day in the hope of a quick indexation. In their help article, Google explicitly point out that a certain quota applies to the submission of new URLs, which cannot be expanded by frequent pinging.
Conversely, I can also have individual URLs removed via Search Console. With the URL Removal Tool, I can arrange for individual URLs to no longer be found in the Google Index. However, this procedure is temporary, a permanent removal of the URL is not possible via this tool. To achieve this, further steps must be taken, such as the “noindex” instruction already described or sending the status codes 404 or 410.
Google Hacking: what is already indexed?
Google hacking actually sounds much more dramatic than it really is. However, the headline has a very real background, in addition to a transparent attempt to attract attention. At the time of its publication, the book “Google Hacking” by Johnny Long (2005) was a nice guide on how to find content in the Google index that definitely had no place there. This was not only relevant for SEO: sensitive data ended up again and again in the not yet fully developed Google index and made companies vulnerable to corresponding attacks.
Since that time, Google has become better and better and simple queries that could be used to retrieve passwords and the like have not worked for a long time. But certain queries still exist using search operators that make searching the index and thus indexing control much easier. Here are some of the most important statements:
– Site:domain.de – this query lists all pages that can currently be found in the index for this domain.
– Intitle:keyword – this query shows URLs with a specific keyword in their title tag.
– Site:domain.de keyword – with this combination I find URLs of a domain that are listed for a certain keyword. Helpful for internal linking, for example, to find suitable linking pages.
– Filetype:xml – finds XML files on a domain, for example the XML sitemap. This can of course be used for all possible file types
– Inurl:keyword – displays URLs containing a certain keyword. Can of course also be linked to the site: Operator
Index Cleanup: now it’s time to clean up!
Again and again, reports appear on the web about how large and wide-reaching sites have improved their performance in search engines by removing content. Just recently, a post by Hanns Kronenberg, Senior SEO Manager at Chefkoch, appeared on Facebook about the ongoing SEO Panda diet.
Fabian Jaeckert, who interviewed him about this for his Content Performance Podcast, quotes Hanns in a LinkedIn post as follows:
“I think that we know better which URLs are valuable and which have less added value. I think Google can figure that out too, but then they test en masse and we lose consistency and stable ranking signals because of that. That’s where it’s better to help Google.” By his own admission, this approach works and the really important pages improve in ranking.
Which pages do not belong in the index? As is so often the case in SEO, the correct answer here is “it depends”. Each SEO recommendation must always be evaluated individually with regard to the domain in question. But generally speaking, one can name a few page types for which it is very likely that they have no place in the Google index. These would be search results pages, for example. It makes no sense to have your own search results pages indexed. On the domain side, this leads to an abundance of thin and duplicate content, since the automatically generated pages are not individualised. On Google’s side, it leads to a situation where search result pages are delivered to a search engine, which is about as useful as ordering a table at the Italian restaurant and then bringing your own homemade pizza.
The same applies to filter pages and sorting, although caution is advised here, as it can make sense in individual cases to have filter results indexed.
Of course, duplicates of pages should not end up in the index. These are often caused by parameter URLs or other technical weaknesses. It is not a matter of “copying” textual content, but often technical deficiencies that lead to an accumulation of duplicate content on the pages of a domain. During a crawl, such errors can often be found very easily, as markers such as duplicate title tags or duplicate descriptions make the problem clear.
Technical weaknesses also often lead to empty pages or pages with extremely little content (thin content). These should also not normally end up in the Google index. During a crawl, these can be recognised not only by the patterns already mentioned but also, for example, by a low word count.
As we can see, search engine optimisation is not only about being found as well as possible. It is also essential that what is in the search engine index is relevant and of high quality. The best thing to do is to take a look for yourself using the search operator site:your-domain.com. Is every hit that Google returns content that you want to present to your visitors and customers?
Happy clean up!
Foto: Jilbert Ebrahimi